Azure Kubernetes Service アップグレード戦略 2021夏版
何の話か
AKS(Azure Kubernetes Service)のアップグレード戦略を、今後の展望も踏まえ整理します。クラスターのBlue/Greenアップグレードなどリスク緩和手段を整える重要性は従来から変わりませんが、負担を軽減するため、自動アップグレードの適用を意識する段階にあると考えています。
なお、アップグレードのリスク、インパクト評価は使い手によります。「全てのアップグレードをクラスター新規作成で行う」という戦略もあれば、「インプレース中心。当たらなければどうということはない」というユーザーもいらっしゃいます。条件や方針、環境に合わせ、妥当な戦略を検討してください。
背景
Kubernetesは2014年の初回コミットから7年経った2021年夏時点においても、活発に開発されているオープンソースソフトウェアです。バージョン1.22からリリースサイクルがおおよそ15週になり、若干落ち着きますが、それでも年間3回の大きな機能変更を意識する必要があります。たとえば、1.22ではIngressなど利用ユーザーが多いであろうAPIの廃止が予定されています。いま動いているシステム、アプリケーションが影響なくアップグレードできるか、変更が必要か、ユーザーは評価、対応しなければなりません。
AKSは“N-2"サポートポリシーを採用しています。(N (最新リリース) - 2 (マイナー バージョン))がサポート対象なので、短期間で廃止するシステムでない限り、アップグレードは避けられません。
AKSはアップグレード作業の負担軽減のため、クラスターのアップグレード機能を提供しています。ですが、その方式はインプレースであり、動いているクラスターに変更を加えます。ダウングレードは、できません。
そこで、アップグレード作業のリスク緩和を目的とした
- 新規クラスターを新バージョンで作成し
- アプリケーションの動作確認を行った後
- トラフィックを新規クラスターに向け
- 安定後に旧クラスターを消す
という方式があります。いわゆる"Blue/Green"デプロイメントです。様々なパターンがありますが、以下は最近、わたしが公開した参考実装です。
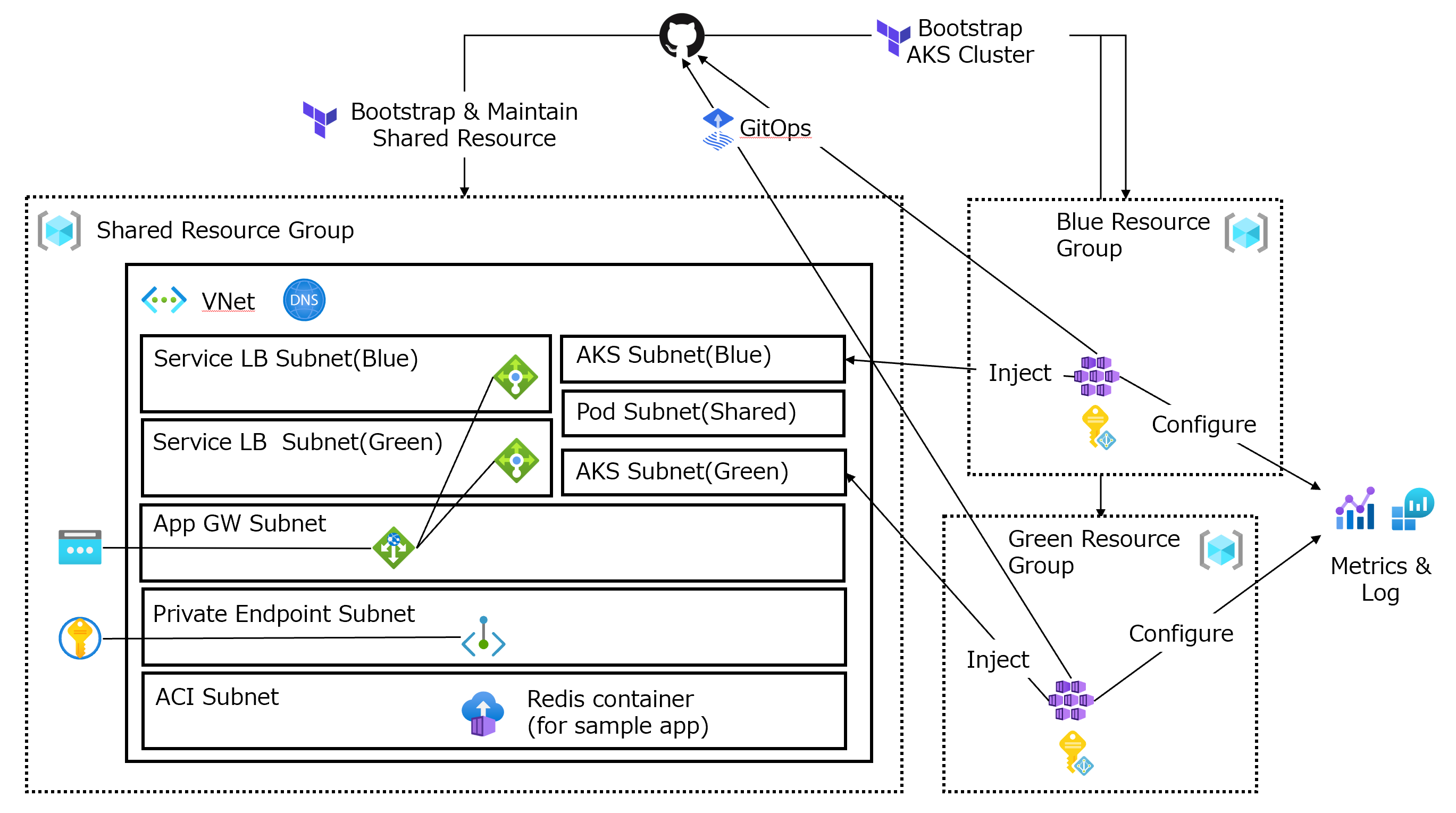
Sample implementation of Azure Kubernetes Service “anti-DRY” bootstrap & maintenance strategy
IaC(Infrastructure as Code)やKubernetesの設計、運用を手の内に入れるまでは、敢えてコードをDRY(Don’t Repeat Yourself)にしない手もある、というコンセプトで作り公開しましたが、AKSのBlue/Greenアップグレードの参考になると思います。
とはいえ、仕組みを確立しリスクは緩和できても、その作業を短い周期で行いたくはない、が人情でしょう。できればもっと楽したい。コードによって環境を迅速に再現、リカバリする手段を確立できているのであれば、アップグレードの内容によってはインプレースで、Azure任せで自動実施してもいいのではないか、というのが、この記事の動機です。
AKSにおけるアップグレード、メンテナンスの現状整理
AKSでアップグレードやメンテナンスの対象となる要素は大きく分けて、マスターとノードです。それぞれ、Kubernetesのバージョンアップ有無で内容が異なります。
- マスター(Kubernetesバージョンアップを伴わない)
- マスター(Kubernetesバージョンアップを伴う)
- ノード(Kubernetesバージョンアップを伴う)
- ノード(Kubernetesバージョンアップを伴わない)
1は、マスターコンポーネントに対するセキュリティやバグの修正パッチ、Azure連携機能の追加が主です。おおむね週次で自動的に行われており、GitHubにチェンジログが公開されています。Kubernetesのバージョンを変えず、短時間で実施されるためインパクトが小さく、気づいていないユーザーも多い印象です。アップグレードというよりは、メンテナンスです。
このメンテナンスは、実施時間を指定できるようになりました。現時点ではプレビュー機能で制限事項もありますが、可能な限り利用者の少ない夜間に実行したい、また逆に、何か起こっても担当者がすぐに対応できる平日昼間を指定したい、などのニーズに合います。
そして2と3は、Kubernetesのバージョンアップを伴う、影響の大きな作業です。従来、ユーザーがポータルやCLIから手動で実施する作業でしたが、アップグレードチャネルを設定することで、自動化も可能になりました。チャネル指定機能は、現時点ではプレビューです。
チャネルはアップグレードのアグレッシブさに応じ、none(既定)、patch、stable、rapid、node-imageから選択できます。たとえばpatchを指定すると、バージョン1.17.7を実行しているとき、1.17.9、1.18.4、1.18.6、1.19.1が利用できる場合、クラスターは 1.17.9 に自動でアップグレードされます。
ノードのアップグレードは、既定ではノードプールを構成するVMSSに1ノードを追加し、既存ノードをdrainして行われます。1ノードずつ行うため、プールのノード数が多い場合にアップグレードにかかる時間が長くなるおそれがありますが、サージ値の指定によって短縮できます。サージ値の増加に応じ、複数ノードでdrainが同時に行われるため、アプリケーションへの影響は考慮してください。
なお、この自動アップグレードは、1の計画メンテナンスで指定したスケジュールを加味して実行されます。
最後に4ですが、ノード(Linux/Ubuntu、Windows)のVMイメージの更新です。AKSではおおむね週次で新規ノードイメージの公開が行われ、Kubernetesのバージョンアップとは別に適用できます。内容はチェンジログで確認できます。セキュリティ関連更新が主目的です。ノードイメージの更新にはOSカーネル関連だけでなく、Kubernetes関連コンポーネントも含まれるため、定期的に行ったほうがよいでしょう。なお、OSの自動セキュリティアップデート機能やkuredと併用できます。
ノードイメージのアップグレードは、パッチをあてるのではなく、ノードを新しいイメージで再作成します。3と同様の方式で行われ、サージ値を指定できます。
自動アップグレードをいかに活用するか
プレビュー段階ではありますが、アップグレードの自動適用、スケジュール指定機能は運用負担の軽減の観点から、検討したいところです。論点は、自動化するリスクと得られる価値とのバランスをどう考え、方針を作るか。以下は、わたしの個人的な方針です。
IaCによる環境再現、リカバリ方式の確立が前提
備えがあれば、リスクはとりやすくなります。また、自動化された作業のリカバリは、自身が確認しながら行ったそれと比較して難しくなりがちです。よって、いざという時に備え、迅速にクラスターを再作成できる仕組みを整備しておきましょう。実際問題、何らかIaCを実現する手段は必要と考えます。以下のポイントを考慮しておくと、作り直しが容易です。
- クラスター内でデータ、ステート、構成情報を永続化せず、クラスター外部で行う
- データベース、ストレージ、シークレットストア、ソースコード管理など、各種マネージドサービスを活用する
- 関連チームの作業省力化も意識する
- たとえば、有事にアプリケーション開発チームに再セットアップをお願いするのは心苦しいもの
- クラスター、基盤関連リソースだけでなく、アプリケーションの再セットアップも手段を確立しておく (GitOpsなど)
- 監視や監査の継続性も意識する
- メトリックやログがクラスター再作成によって失われないようにする
- 各種マネージドサービスを活用する
- 監視など運用周りの設定もコード化しておく
- 例外として手作業でいいや、と妥協してしまうと、この作業の面倒さが後々足を引っ張ります
実装は先ほど紹介したサンプルなどを参考にしてください。
パッチバージョン、ノードイメージのアップグレードから自動化する
1.22の変更内容からも実感できるように、現状、マイナーバージョンアップには破壊的な変更が含まれます。となると、マイナーバージョンアップをAzureに任せて放置、という方針はまだ高リスクでしょう。そこで小さく実績、成功体験を積み重ねる意味でも、パッチバージョン、ノードイメージのアップグレードから自動化するのがよいのでは、と考えます。パッチバージョンやノードイメージの更新には緊急性の高いセキュリティ対応が含まれがちなので、ここを自動化するだけでも負担は大きく軽減されるはずです。
なお、バージョンアップをAzureに任せると、環境を作るコードと現状の不一致が起こります。それは認めます。自動アップグレードで何か起こった時に、アップグレード前に戻せる(作り直せる)ことが価値だったりもするので。理想を追い過ぎず、自動アップグレード後、安定したら実環境に合わせてコードのバージョンを更新する、という運用もありなのでは、と考えます。
ノード更新時のアプリケーションへの影響を把握、対処する
先述の通り、AKSのアップグレード機能において、Kubernetes、ノードイメージのアップグレード実行中はノード追加とdrain、ノード削除が行われます。この際の影響を把握することが重要です。
- セッションアフィニティに依存しないなど、Pod上のアプリケーションがステートレスであること
- Pod削除時に、受け付けたリクエストへのレスポンスが終わるまで待つ仕組みがあること
- アップグレード中に要求が失敗したり接続が切れても、要求元がリトライすること
が、影響を回避する設計の基本です。ですが、それを意識して設計したとしても、実際に動かしてみないと挙動が分からないケースもあるでしょう。
たとえば、
- ステートレスな作り
- Podのレプリカ数、PodDisruptionBudgetも十分
- シグナルハンドリング、terminationGracePeriodSeconds設定など、graceful shutdownも考慮されている
という場合でも、アップグレード中に新規リクエストが一時的に失敗するケースがあります。以下はGCPでのIssueですが、AKSでも起こりえます。アップグレード中に新規リクエストがタイムアウトしてしまう、という問題です。既存リクエストへのレスポンスには影響ありません。
Terminating pod causes network timeouts with GCP L4 LB and externalTrafficPolicy: Local
service.type: LoadBalancerで公開しているServiceは、トラフィックの送り先であるノードの死活確認をロードバランサーのプローブに依存しています。そして、アップグレードの際のノード削除がプローブ間隔、判断の隙間に入ってしまうと、ロードバランサが停止、削除されたノードへトラフィックを送り、タイムアウトまで待ってしまう可能性があります。IssueではexternalTrafficPolicy: Localのケースが議論されていますが、LocalではなくClusterに変えても、現時点でノード削除時はこの問題を回避できません。GCPにおいて、ロードバランサーのプローブ、判断間隔を短くするワークアラウンドが提案されていますが、行ったり来たりの副作用が懸念されます。なお、AKSの場合は、ロードバランサのプローブに関する設定をカスタマイズできないので、このアイデアは適用できません。クライアントやApplication Gatewayで副作用の起きない範囲で早めにタイムアウト、リトライを行うといいでしょう。
このように、実際にアップグレード中の挙動を確認しないと気づきにくいこともあるので、テストをおすすめします。
Kubernetesの進化のサイクルへの追従、アップグレードは、企業における活用において大きな課題でした。AKSの支援機能が、その問題の解決に寄与することを願っています。プレビュー段階の機能が多いですが、いずれ来るGAに備え、開発、検証環境などで知見を得ておくのも、よいのではないでしょうか。