Daprの回復性を支える仕組み 現状と展望
このエントリは、Dapr Advent Calendar 2021の参加作品(12/11)です。
何の話か
クラウドでは、一過性の障害が起こりがちです。その原因は、以下のドキュメントで具体的に説明されています。
故障や負荷だけでなく、メンテナンスも原因となり得ます。
しかし多くの場合、クラウド内部で復旧や切り替えが行われます。呼び出し元が少し時間をおいてからリトライすれば、高い確率で成功するでしょう。よって、リトライなど回復性向上の仕組みを、アプリケーションに組み込むことが推奨されています。
Daprをクラウド上で使いたい、という人は多いでしょう。そしてDaprは、分散アプリケーションを作る開発者の負担を減らすために生まれました。アプリケーション開発者が「回復性に関わるあれこれは、Daprさんのほうで面倒を見てくれないかな」と思うのは自然です。
そこでこのエントリでは、Daprの回復性を高める仕組みについて、現状と展望をまとめます。
なお展望について、Daprコミュニティでの議論を直に見たいのであれば、ぜひ以下のIssueを読んでください。よく整理された提案です。
[Proposal] Resiliency policies across all building blocks
前置きが長くなりました。当エントリの目的は、いま紹介したIssueを読む時間と、 現状調査をする余裕がない人向けのまとめです。また、Daprの回復性について関心を持つきっかけになればいいな、と思いながら書いています。
現状 (Dapr v1.5)
呼び出し元側のDaprランタイム(サイドカー)の実装が、今回整理する対象です。呼び出す先の回復性は、Kubernetesの各種回復機能など基盤を活用して担保するものとします。
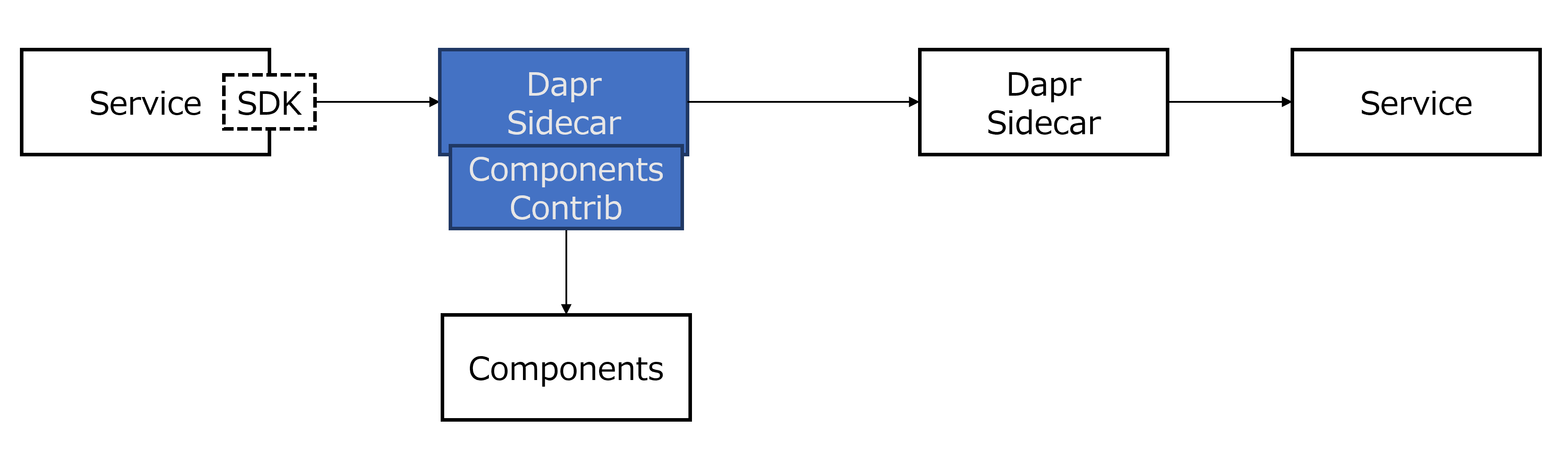
呼び出しパターンは、サービス呼び出し(Service-to-service Invocation)と、コンポーネント呼び出しに分けられます。それぞれの現状は以下の通りです。
- サービス呼び出しは、失敗したら1秒空けてリトライする(3回まで)
- 実装: invokeWithRetry
- 定義は定数
- コンポーネント呼び出しは、それぞれの実装による
- ビルディングブロック別 各コンポーネント向け仕様
- リトライに関するパラメータを指定できるものもある
- ビルディングブロック別 各コンポーネント向けパッケージのソースコード(components-contrib)
- 各ビルディングブロックのディレクトリの下に、コンポーネントごとのGoパッケージがある
- コンポーネント向けパッケージの多くは個別にリトライ機能を実装している
- dapr/kitにretryパッケージがあるが、利用は任意
- 使っている例: Azure Service Bus Queues binding
- 使っていない例: Azure Storage Blob binding
- ビルディングブロック別 各コンポーネント向け仕様
このように、面倒を見てくれるいっぽう、課題もあります。
課題
- サービス、コンポーネント間で仕様や実装の一貫性がない
- 仕様に明記されておらず、実装の確認が必要なものがある
- リトライ回数や間隔など、パラメータを指定できないものがある
- リトライの実装が多いが、サーキットブレイカーなど他のパターンも欲しい
ということで、仕切り直しましょう、という状況です。
展望
前述した提案で、課題解決の方向性と進め方が議論されています。
回復性を高める仕組みは利益が大きい反面、提案のCautions/Considerationsで触れられている通り、リスクも含みます。リトライによる重複書き込みが代表的です。なので慎重に、段階的なアプローチが検討されています。
- フェーズ1: 回復性に関するポリシーを共通化し、各ビルディングブロックやコンポーネントに割り当てられるようにする
- 回復性ポリシーをKubernetesのカスタムリソースとして定義
- タイムアウト、リトライ、サーキットブレイカーに関するポリシーから
- フェーズ2: API固有のポリシーで、上書きできるようにする
おそらくフェーズ1のリリース後に、多くのフィードバックがあるでしょう。それを見越し、フェーズ1では基本的な機能にフォーカスしています。
フェーズ1
フェーズ1では、以下のようなカスタムリソースが提案されています。代表的な部分を抜き出します。コメントは削っていますが参考になるため、ぜひ原文もご覧ください。
apiVersion: dapr.io/v1alpha1
kind: Resiliency
metadata:
name: daprResiliency
scopes:
- app1
- app2
...
policies:
timeouts:
general: 5s
important: 60s
largeResponse: 10s
retries:
general: {}
pubsubRetry:
policy: constant
duration: 5s
maxRetries: 10
retryForever:
policy: exponential
maxInterval: 15s
maxRetries: 0
...
circuitBreakers:
general: {}
pubsubCB:
maxRequests: 1
interval: 8s
timeout: 45s
trip: consecutiveFailures > 8
buildingBlocks:
services:
appB:
timeout: general
retry: general
circuitBreaker: general
...
components:
statestore1:
timeout: general
retry: general
circuitBreaker: general
pubsub1:
retry: pubsubRetry
circuitBreaker: pubsubCB
...
タイムアウト、リトライ、サーキットブレイカーのポリシーをそれぞれ定義し、ビルディングブロックを構成するサービスやコンポーネントに割り当てます。タイムアウトを判断するまでの時間や、リトライ間隔を固定にする/指数的に増やすなど、目的に応じたポリシーを作れます。
現時点でフェーズ1は、2022/1に予定されているDapr v1.6でのリリースを目指しています。もちろんこのカスタムリソースを使うように、各コンポーネント向けパッケージでも対応しなければいけませんが、まずは重要な一歩目です。
フェーズ2
フェーズ1のフィードバックによりますが、現時点ではAPI固有のポリシー定義による上書き機能が予定されています。代表例を抜き出します。
...
apis:
invoke:
- match: appId == "appB"
rules:
- match:
request.method == "GET" &&
request.metadata.count > 1000
timeout: largeResponse
retry: largeResponse
- match:
request.path == "/someOperation"
retry: someOperation
...
サービス呼び出しのポリシーを、リクエストのメソッドやパスに合わせて個別のポリシーで上書きする、という使い方は分かりやすい例ですね。
いま意識したいこと
以上、Daprの回復性を支える仕組みについて、現状と展望をざっと整理しました。それを踏まえ、いまDaprを使うなら、以下を意識するといいかな、と思います。
- 各コンポーネント向けパッケージが、どのような回復性向上機能を持っているか、選定時に確認する
- 呼び出し元のサービス、アプリケーションで実装すべき機能を検討する
- 将来の拡充を期待するにせよ、最低限のエラーハンドリングは必要
- SDKとその使い方を参考にする
- SDK視点でも既知の問題や課題、経緯を確認しておくとなお良し
- 例: Remove retry options from state apis - Go SDK
- 展望として紹介した回復性ポリシーはすぐに使えるわけではないが、状況をウォッチしておく
- 導入タイミングを見極める
Enjoy Dapr!